
文字列から特定の一部のみ抽出したいときに問題となる場面のひとつが、「検索文字列が複数ある場合」です。
「本社–管理本部–総務部」や「東京都_港区_芝公園」といった文字列から、「総務部」や「芝公園」のみを抽出するには少しテクニックが必要です。本記事では、検索文字列が複数ある場合に、特定の一部だけを抽出する方法を解説します。
はじめに
技術的に大切なポイントは赤色のアンダーラインで、アイデアとして大切なポイントは黄色のアンダーラインで強調しています。関数の記述は黒いボックス内にあります。
ご自身の用途に合わせて必要な部分をチェックしてみてください。
完成形の概要
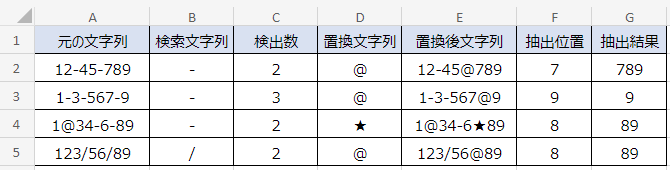
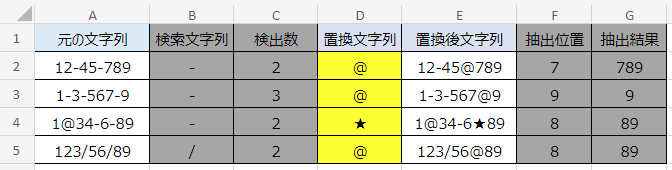
一例として、複数の検索文字列がある文字列から、最後の検索文字列以降を抽出する表です。今回の例で検索文字列に指定したのは「-(ハイフン)」または「/(スラッシュ)」です。
すべてをまとめた数式は本記事の最後(「関数をすべてネストした場合」)で紹介しています。
ちなみに、分割するとよくわかるのですが、ひとつひとつは大した数式ではありません。関数についていくらかの知識がある方なら、充分に理解できる内容だと思います。
検索文字列は、漢字、ひらがな、数字、アルファベット、記号など何にでも対応できます。2文字以上を設定することも可能です。
関数をネスト(入れ子)すれば、B~F列は不要ですが、ネストしすぎると人間には理解しにくい数式になってしまいます。会社などで利用する場合は業務の引き継ぎなどを考慮して、上記の表のように作業セルを設けて数式を分割することをおすすめします。
ちなみに、次の条件に当てはまる場合は、より簡単な数式で抽出できます(本記事の数式でも対応できます)。
- 検索文字列は複数個あるが、個数は決まっている場合
- 検索文字列は複数個あるが、検索文字列の指定の仕方を工夫すれば1つに絞れる場合
抽出の仕組みの全体像
本記事の処理では、C列からG列にかけて、4段階の計算をして抽出しています。それぞれの数式の役割は次のとおりです。
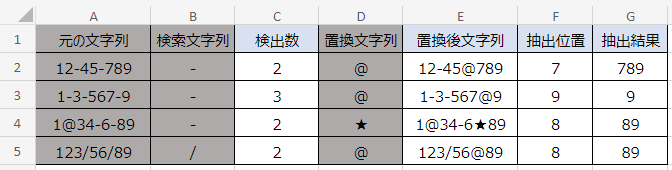
C列:検索文字列の個数を調べる。
E列:C列の計算結果を利用して、一番最後の検索文字列だけを別の文字に置換する。
F列:E列の計算結果を利用して、抽出する文字列の開始位置を調べる。
G列:F列の計算結果を利用して、文字列を抽出する。
基本的な構造としては、FIND関数で検索文字列の位置を調べ、その次の位置からMID関数で切り取るというものです。しかし、FIND関数の機能上、検索文字列が複数ある状態では2つ目以降の位置がわかりません。そこで、SUBSTITUTE関数で特定の検索文字列を別の文字に置換し、狙った位置を調べています。

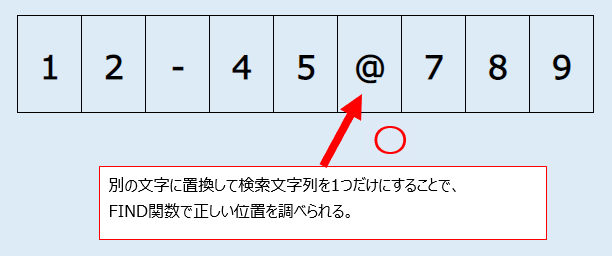
C列の数式
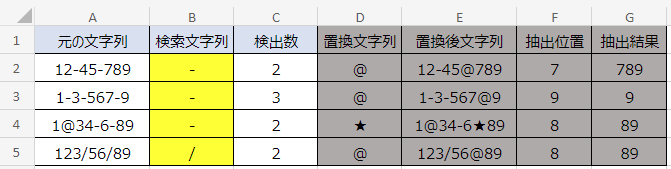
セルC2の数式は次のとおりです。
=LEN(A2)-LEN(SUBSTITUTE(A2,B2,""))C列では、LEN関数を利用して検索文字列の個数を調べています。
(1)LEN(A2):元の文字列(12-45-789)の文字数を計算しています。計算結果は9。
(2)LEN(SUBSTITUTE(A2,B2,””)):SUBSTITUTE関数にて、元の文字列からセルB2で指定した検索文字列「-」を削除した文字列(1245789)の文字数を計算しています。計算結果は7。
検索文字列を変更したい場合は、B列の値を変更してください。B列を使用したくない場合は、数式内の「B2」の部分を「”-“」に替えれば同じ結果が得られます。
「元の文字列の文字数」から「検索文字列を除く文字数」を引くことで、検索文字列の総数を調べています。文字列の中から特定の文字の文字数を調べる関数がないため、このような面倒な処理が必要です。
E列の数式
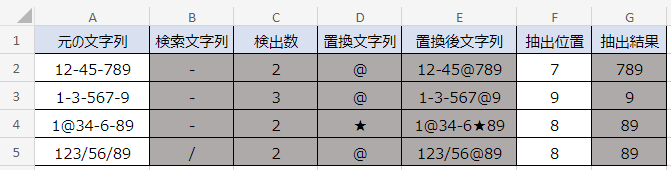
セルE2の数式は次のとおりです。
=SUBSTITUTE(A2,B2,D2,C2)E列では、SUBSTITUTE関数で最後の「-」だけを「@」に置換しています。
ポイントは第4引数(置換対象)の「C2」の部分です。C列で検索文字列の「-」の総数を計算したのは、何個目の「-」を「@」に置換したらよいかを調べるためです。セルC2の計算結果によって、2個目の「-」のみを「@」に置換できます。
なお、最後の検索文字列ではなく1つ手前の位置で置換したいときは、「C2-1」などで置換する位置を調整するとよいでしょう。
置換後の文字列を変更したい場合は、D列の値を変更してください。D列を使用したくない場合は、数式内の「D2」の部分を「”@”」に替えれば同じ結果が得られます。その場合、必要に応じて「B2」を「”-“」に替えるのも忘れないでください。
なお、置換後の文字列については、元の文字列に絶対に含まれない文字を選択してください。セルA4のような文字列の場合、「@」に置換すると重複するので別の文字(★)を使用します。
置換したにも関わらず文字が重複していると正しい結果を得られません。
F列の数式
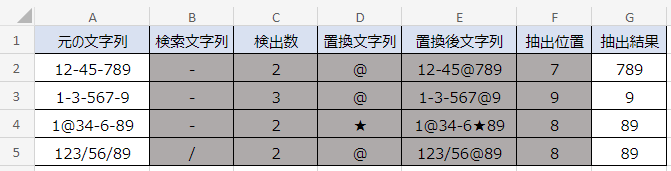
セルF2の数式は次のとおりです。
=FIND(D2,E2)+1F列では、FIND関数で置換後の文字列の位置を調べています。
抽出の開始位置は置換後の文字列の次の文字からなので、FIND関数の計算結果に+1をしています。
G列の数式
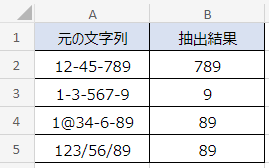
セルG2の数式は次のとおりです。
=MID(A2,F2,99)G列では、MID関数で元の文字列から必要な部分だけを抽出しています。
抽出の開始位置はF列で計算済みなので、計算結果を参照するだけです。第3引数(文字数)については、抽出する文字数が何文字でも収まるような大きい数字を入れておくとよいでしょう。
関数をすべてネストした場合
関数をすべてネストした場合の数式は次のとおりです。
=MID(A2,FIND("@",SUBSTITUTE(A2,"-","@",LEN(A2)-LEN(SUBSTITUTE(A2,"-",""))))+1,99)=MID(A3,FIND("@",SUBSTITUTE(A3,"-","@",LEN(A3)-LEN(SUBSTITUTE(A3,"-",""))))+1,99)=MID(A4,FIND("★",SUBSTITUTE(A4,"-","★",LEN(A4)-LEN(SUBSTITUTE(A4,"-",""))))+1,99)=MID(A5,FIND("@",SUBSTITUTE(A5,"/","@",LEN(A5)-LEN(SUBSTITUTE(A5,"/",""))))+1,99)それぞれの関数についての詳しい説明は上述のとおりです。
「セルB2の数式」をコピーして次の箇所を調整すれば、ご自身の環境に合わせられます。
数式内の4か所の「A2」:抽出したい元の文字列があるセルを指定する。
数式内の2か所の「”@”」:元の文字列に絶対に含まれない任意の文字を指定する。
数式内の2か所の「”-“」:元の文字列から抽出するためのキーとなる文字列を指定する。
数式内の「99」:抽出後の文字列が99文字以上になるのであれば、より大きな数字を指定する。
おわりに
データベースにある文字列が長いほど、本記事のような抽出をしたい場面が増えます。元の文字列の条件によってはより簡単な数式で済む場合もありますが、とりあえず処理できればよいというのであれば、本記事で紹介した数式を調整して使ってみてください。
本記事で使用した4つの関数は利用しやすいものですので、この機会に仕組みを理解しておくと今後の役に立つでしょう。


コメント